State-of-the-art Large Multi-Modal Models (LMMs) have demonstrated exceptional capabilities in vision-language tasks. Despite their advanced functionalities, the performances of LMMs are still limited in challenging scenarios that require complex reasoning with multiple levels of visual information. Existing prompting techniques for LMMs focus on either improving textual reasoning or leveraging tools for image preprocessing, lacking a simple and general visual prompting scheme to promote vision-language coordination in LMMs. In this work, we propose SCAFFOLD prompting that scaffolds coordinates to promote vision-language coordination. Specifically, SCAFFOLD overlays a dot matrix within the image as visual information anchors and leverages multi-dimensional coordinates as textual positional references. Extensive experiments on a wide range of challenging vision-language tasks demonstrate the superiority of SCAFFOLD over GPT-4V with the textual CoT prompting.
⚙️ SCAFFOLD Prompting

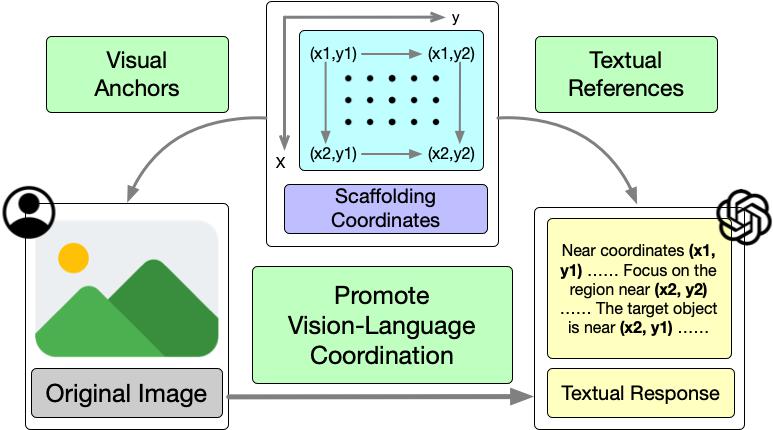
Scaffold is a simple and versatile visual prompting scheme to promote the coordination between vision and language in LMMs. SCAFFOLD overlays a dot matrix onto the input image, and each dot is labeled with its multi-dimensional Cartesian coordinate. The dot matrix on the image forms the SCAFFOLD that indicates relative visual positions for LMMs. The overlaid coordinates are also included in the textual prompt, which explicitly strengthens the connection between visual and textual information for LMMs. The LMMs are thus steered to leverage the coordinates to solve different vision-language tasks. In this way, SCAFFOLD provides a scaffold to promote vision-language coordination in LMMs. See our paper for more details.
Visually, we enhance each input image with a uniformly distributed rectangular dot matrix, where each dot is labeled with multi-dimensional Cartesian coordinates. These dots serve as visual positional anchors, while their coordinates are utilized as textual references in textual responses.
Textually, we prepend textual guidance to task instructions for LMMs. This includes a brief description of the dot matrices and coordinates, accompanied by several general guidelines for their effective use.
🚀 Use Cases
Here are some cases from our experiments, illustrating the functions of SCAFFOLD prompting.



📂 Experiments
To demonstrate the effectiveness of Scaffold, we conduct extensive experiments on top of GPT-4V on a range of challenging vision-language tasks, including Spatial Reasoning, Compositional Reasoning, Fine-Grained Visual Understanding and Hallucination. For each task, we select several benchmarks for an extensive evaluation. See our paper for more details.
Diversified Benchmarks: Crucial Capabilities
- Spatial Reasoning evaluates LMM capability to infer spatial relationships between objects. Selected benchmarks include MME (Position split) (Fu et al., 2023a), Visual Spatial Reasoning (VSR) (Liu et al., 2023a) and EgoThink (Spatial split) (Cheng et al., 2023).
- Compositional Reasoning requires LMMs to identify object attributes and their interrelations. Selected benchmarks include Winoground (Thrush et al., 2022), WHOOPS! VQA (Bitton-Guetta et al., 2023), CLEVR (Johnson et al., 2017).
- Fine-Grained Visual Understanding requires LMMs to perform visual search and precisely perceive fine-grained visual details. Selected benchmarks include V* Bench (Wu and Xie, 2023) and Spotting Differences (CrazyGames).
- Hallucination measures the tendency of LMMs to generate hallucinatory or illusory perceptions. Selected benchmarks include POPE (Adversarial Subset) (Li et al., 2023), HallusionBench (Guan et al., 2023) and Mementos (Wang et al., 2024).
Overall Results: Boosted Performance
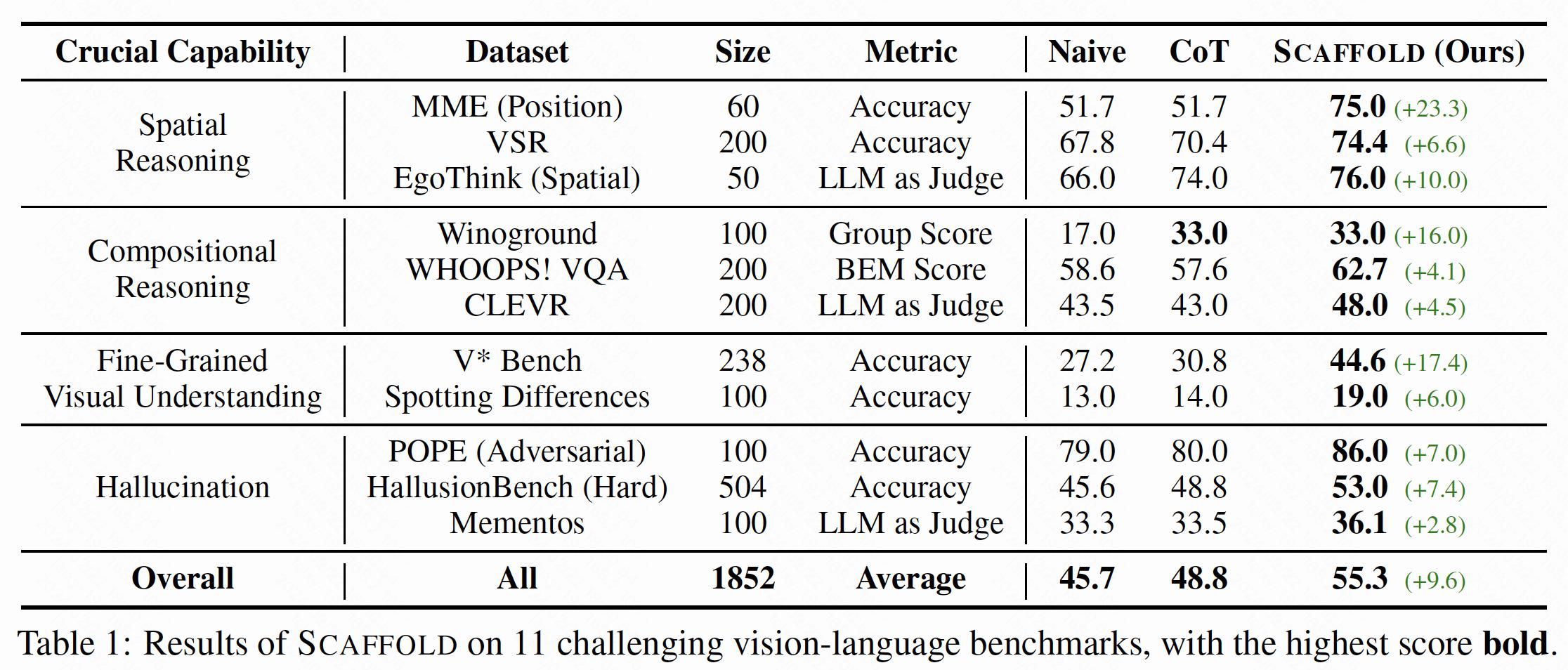
The results demonstrate that SCAFFOLD significantly enhances the visual capabilities of LMMs, surpassing zero-shot CoT in most evaluated benchmarks. With naive and textual CoT prompting averaging 45.7 and 48.8 respectively, SCAFFOLD successfully obtains an overall improvement of 9.6.
Combined with Active Perception
In complex visual environments, humans would proactively engage with their surroundings to enhance scene understanding, like zooming in or changing perspectives. Similarly, we recognize that LMMs should possess such capabilities in realistic scenarios and propose that SCAFFOLD can function as a scaffold for effective active perception.
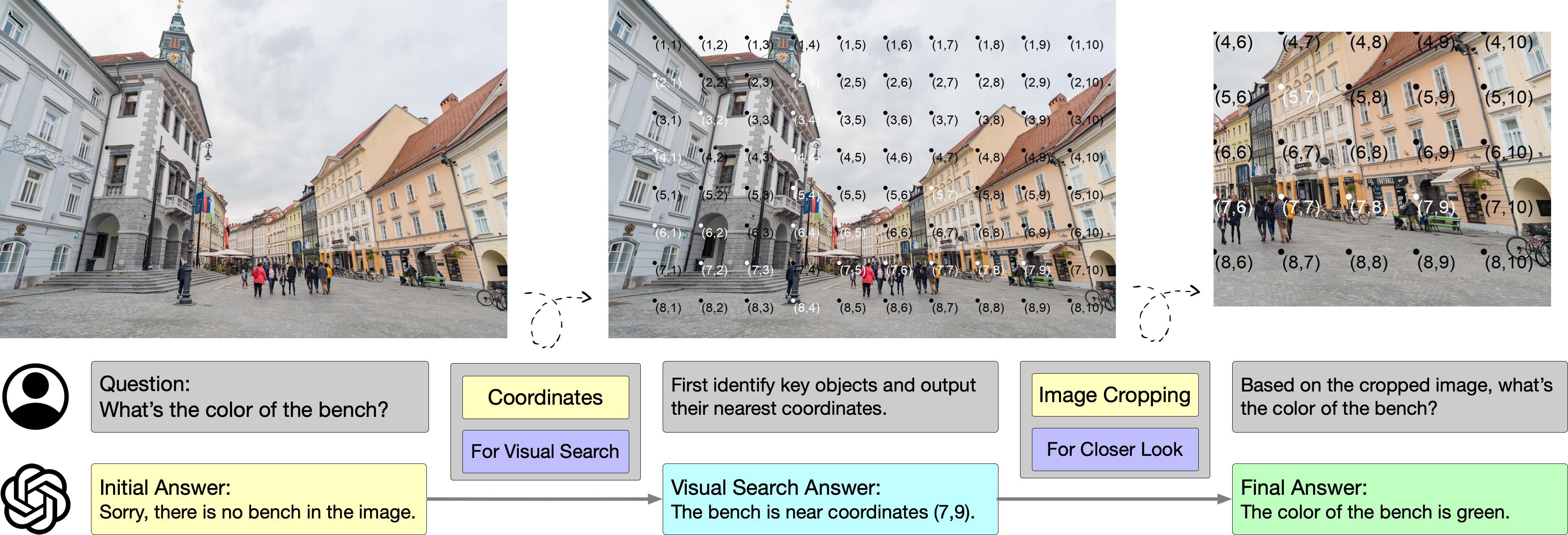
To validate this, we integrate SCAFFOLD with active perception in the experiments on the direct_attributes subset of V* Bench, which requires LMMs to perceive fine-grained details in high-resolution images. We adopt two metrics to measure LMM performance, including Not Found Rate representing the percentage of invalid responses, and Success Rate representing the percentage of correct responses.
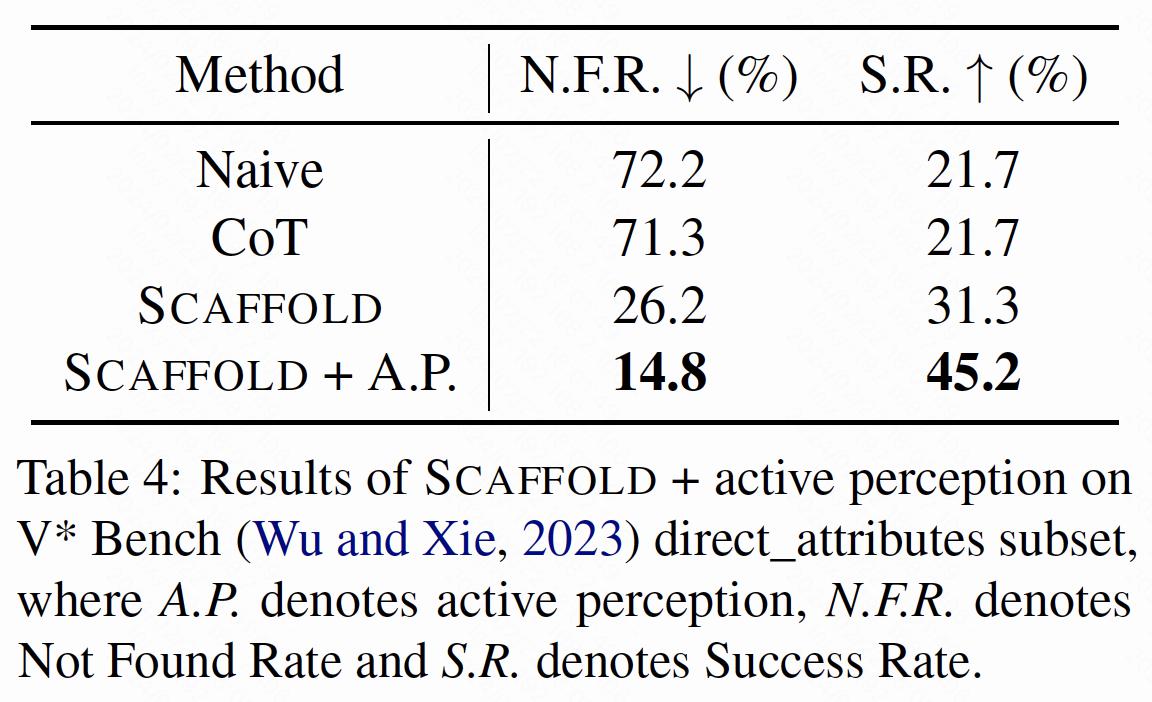
Scaffold prompting combined with active perception unfolds in two phases: initial visual search to locate the target details, followed by cropping the image around the pinpointed coordinates to closely examine and identify the target attributes. The results reveal a performance enhancement of 14.1% compared with SCAFFOLD alone, underscoring the utility of coordinates in facilitating active perception.
👏 Citation
@article{lei2024scaffolding,
title={Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models},
author={Xuanyu Lei and Zonghan Yang and Xinrui Chen and Peng Li and Yang Liu},
journal={arXiv preprint arXiv:2402.12058},
year={2024},
}
Acknowledgements: This website is adapted from UA2.